TOM Software Architecture¶
The goal of the TOM Toolkit is to make developing TOMs as easy as possible while providing the flexibility needed to tailor each TOM to its specific science case. The motivation for the TOM Toolkit is discussed on the about page.
The TOM Toolkit (referred to as “the toolkit”) provides a framework for developing web applications that serve the purposes described in the motivation. This means when users interact with a TOM they will be doing so via a web browser or through other internet-based protocols. Web-based technologies allow developers to create rich user interfaces, simplify distribution and choose from a huge variety of programming languages and frameworks.
Python has become the go-to language for many in science. Fortunately, Python also enjoys widespread popularity in web development communities. This provides a unique opportunity for “Pythonistas” to develop scientific codebases which integrate seamlessly with web-based technologies. One need look no further than the success of the Jupyter project to see evidence of this.
There has been a lot of development surrounding Python and the web in the last two decades. One framework in particular, Django has emerged as one of the more popular choices for web development. Django is well known for its maturity, ease of use and modularity.
Instead of reinventing the wheel, it often makes sense to build on the proven work of others. Thus, it was decided that the toolkit would build on top of the Django framework. This provides several advantages:
The toolkit does not need to re-implement generic functionality that Django already provides such as template rendering, routing, object relational mapping, or even higher-level functionality like user accounts and database migrations.
TOM developers get to take advantage of the massive amounts of existing knowledge that already exists for Django projects. In fact, much of the extra functionality that a TOM developer might want to implement need not be dependent on the the toolkit at all, but can instead be developed by referring to the excellent documentation Django provides.
There are thousands of Django packages already written that can be used in any TOM project. If a TOM developer wants to be able to generate dynamic plots, or allow their users to login with Google, or even turn their TOM into a Slack bot, chances are there is already a package available that might suit their needs.
We highly recommend that developers interested in utilizing the TOM Toolkit familiarize themselves with the basics of Django, especially if they want to customize the toolkit in any significant fashion. The majority of the guides found in the TOM toolkit documentation are simply Django concepts rewritten in a TOM context.
Extending and Customizing the TOM Toolkit¶
As mentioned before, Django is well known for its extensibility and modularity. The toolkit takes advantage of these strengths heavily. In many ways, the TOM Toolkit is a framework within a framework.
After a TOM developer follows the getting started guide they are left with a functioning but generic TOM. It is then up to the developer to implement the specific features that their science case requires. The toolkit tries to facilitate this as efficiently as possible and provides documentation in areas of customization from changing the HTML layout of a page to customizing an OCS facility and forms and even creating a new alert broker.
Django, and by extension the toolkit, rely heavily on object oriented
programming, especially inheritance. Most customization in the TOM toolkit comes
from subclassing classes that provide generic functionality and overriding or
extending methods. An experienced Django developer would feel right at home. For example, the
ObservationRecordDetailView
in the tom_observations module of the toolkit inherits from Django’s
DetailView.
This means TOM developers are able to take full advantage of the power of Django
while still benefiting from the basic functionality that the toolkit provides.
This is why we recommend TOM developers familiarize themselves with Django; most TOM Toolkit features are actually extended Django features.
Plugin Architecture¶
Some areas of the TOM implement a plugin based architecture to support multiple
implementations of a similar functionality. An example would be the
tom_observations` module in which every supported observatory is implemented
as its own plugin. The tom_catalogs and tom_alerts work in the same way: the
module defines the interface and generic functionality and each implementation
fills in its own logic.
This structure makes it easy for developers to write their own plugins which can then be shared and installed by others or even contributed to the main codebase. The gemini.py module is an observation module plugin contributed by Bryan Miller to enable the triggering of observation requests on the Gemini telescope via the TOM Toolkit. Thanks Bryan!
Template Engine¶
The toolkit is able to take advantage of Django’s excellent template engine. Part of the engine’s power comes form the ability of templates to extend and override each other. This means a TOM developer can easily change the layout and style of any page without modifying the underlying framework’s code directly. Entire pages may be replaced, or only “blocks” within a template.
Compare these screenshots of the standard target detail page and the Global Supernova Project’s target detail page, the latter taking heavy advantage of template inheritance.
{kind=link}
Data Storage, Deployment and Tooling¶
The toolkit is implemented as a web application backed by a relational database, uses (mostly) server side rendering, and is deployed using wsgi.
The toolkit should support any relational database that Django supports, including MySql, Postgresql, SQLite, and Oracle. There is nothing stopping a TOM developer from supplementing their TOM with additional databases, even NoSQL ones. By default SQLite is deployed because of its ease of use.
For non-database storage (data products, fits files, etc) the toolkit can be configured to use a variety of cloud-based storage services via django-storages. The documentation provides a guide for storing data on Amazon S3. By default, data is stored on disk.
Similarly, deployment works with a variety of servers, including uWsgi and Gunicorn. The documentation provides a guide to deploying to Heroku for those who want to get up and running quickly. Another option is to use Docker: the demo instance of the toolkit is deployed to a Kubernetes cluster and the Dockerfile is available on Github.
On the frontend, the toolkit utilizes the very popular Bootstrap4 css framework for its layout and general look, making it easy to pickup for anyone with experience with CSS. Javascript is introduced sparingly (astronomers love Python!) but is used in various situations to enhance the user experience and enable functionality such as interactive plotting and sky maps.
Django Reusable Apps¶
As previously mentioned, one of the reasons for Django’s popularity is its modularity. Django has the concept of reusable apps which are just python packages that are specifically meant to be used inside a Django project. The majority of the the toolkit’s functionality is implemented in a series of Django apps. While most of the apps are required, some may be omitted entirely from a TOM if the functionality is not desired.
The following describes each app that ships with the toolkit and its purpose.
TOM Targets¶
The tom_targets app is central to the entire TOM Toolkit project. It provides the database definitions for the storage and retrieval of targets and target lists. It also provides the views (pages) for viewing, creating, modifying and visualizing these targets in several ways including the visibility and target distribution plots.
Nearly every app depends on the tom_targets module in some way.
TOM Observations¶
The tom_observations app handles all the logic for submitting and querying observations of targets at observatories. It defines the database models for observation requests and provides some views for working with them. facility.py defines an interface that external facilities (observatories) can implement in order to integrate with the toolkit: gemini.py and lco.py are two examples, and we expect more in the future.
TOM Data Products¶
Straddling both the tom_targets and tom_observations packages is
tom_dataproducts.
This package contains the logic required for storing data related to targets and
observations within the toolkit. Some data products are fetched from on-line
archives (handled by an observatory’s observation module) but data can also be
uploaded manually by the toolkit’s users.
This module handles details such as where data should be stored (locally on disk or in the cloud) as well as displaying certain kinds of data. It also provides code hooks where TOM developers can run their own functions on the data in case specialized data processing, analytics or pipelining is required.
TOM Alerts¶
The tom_alerts app contains modules related to the functionality of ingesting targets from various external services. These services, usually called brokers, provide rapidly changing target lists that are of interest to time domain astronomers. The alerts.py module provides a generic interface that other modules can implement, giving them the ability to integrate these brokers with the toolkit. Currently, there are modules available for Lasair, MARS, SCOUT, and others, with more planned for the future.
TOM Catalogs¶
The tom_catalogs app contains functionality related to querying astronomical catalogs. These “harvester” modules enable the querying and translation of targets found in databases such as Simbad and JPL Horizons directly into targets within the toolkit. The harvester.py module provides the basic interface, and there are several modules already written for Simbad, NED, the MPC, JPL Horizons and the Transient Name Server.
TOM Setup and TOM Common¶
The tom_setup package is special in that its sole purpose is to help TOM developers bootstrap new TOMs. See the getting started guide for an example. The tom_common package contains logic and data that doesn’t fit anywhere else.
Database Layout¶
The following diagram is an Entity-relationship Diagram (ERD). It is meant to display the relationship between tables in a database. In this case, it may help illustrate how the data from each of the toolkit’s packages relate to each other. It is not exhaustive; many tables and rows have been omitted for brevity.
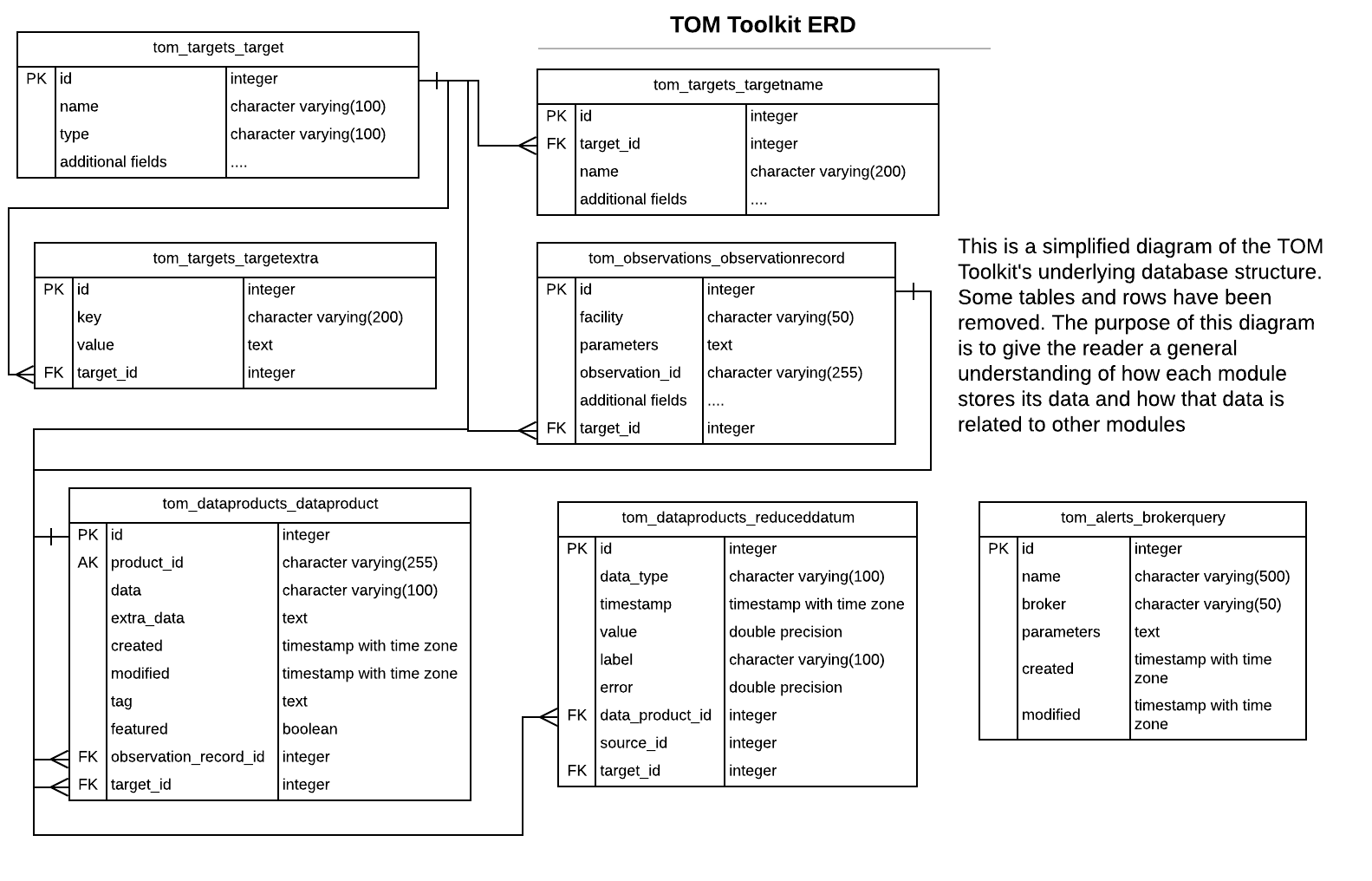
Models¶
Django models are the classes that map to the database tables in your Django application. The TOM Toolkit models and the rationale behind them do are largely intuitive, but may require some explanation.
Target¶
The Target model is relatively self-evident–it stores the data that describes the
targets in your TOM. By default, that includes things like name, type, coordinates, and
ephemerides.
TargetName¶
The TargetName model stores extra names for a target, aka aliases. The corresponding target
is stored as a foreign key.
ObservationRecord¶
The ObservationRecord model describes an individual observation request for a single target.
It stores the target as a foreign key, and can optionally store facility information and the
parameters submitted for the observation.
DataProduct¶
The DataProduct model can refer to a number of different things, but generally refers to a
single file that is associated with a Target and optionally an ObservationRecord. A
DataProduct` has one of a number of tags, which at present include the following:
Photometry, a file containing photometric data
FITS, any FITS file not falling into the other categories
Spectroscopy, a file containing spectroscopic data
Image, a file containing image data, such as a JPEG or PNG
A DataProduct type is file format-agnostic and refers to the data contained in the file,
rather than the format itself. The type is necessary for making decisions on which operations
can be executed using the data in a file.
ReducedDatum¶
A ReducedDatum is a single point of data associated with a Target and optionally a
DataProduct. The single data point is typically a single point of photometry or an individual
spectrum. The ReducedDatum model has the following fields, in addition to its aforementioned
foreign key relationships:
data_typeis maintained on both theReducedDatumandDataProductfor the case when data is brought in from another source, such as a brokerThe
source_nameoptionally refers to the original source of the data. The intent of this field was to track data ingested from brokers, but could potentially be used for other purposes.source_locationoptionally gives a hard location to the source–for a broker, it would be a link to the original alert.The
timestamptime at which the datum was produced.valueis aTextFieldthat can take any series of data. As implemented, photometry is stored as JSON with keys for magnitude and error, but theTextFieldprovides flexibility for additional photometry values on the datum. Spectroscopy is also stored as JSON, with keys formagnitudeandflux.
Feedback and bug reporting¶
We hope the TOM Toolkit is helpful to you and your project. If you have any concerns about implementation details, or questions about your own needs, please don’t hesitate to reach out. Issues and pull requests are also welcome on the project’s GitHub page.